Traditionally programmers have assumed that a TCP packet will either make it to the remote peer error-free or the TCP socket will be detected as failed. However, this has proven a disastrous assumption in the world of cellular networks.
Cellular networks seem to suffer a kind of burst-error mode where whole groups of TCP packets get lost or delayed, while another group makes it through. This seems to confuse the TCP state machines within OS which are optimized for the more rare, single-packet loss of Ethernet. We have Ethereal traces where one can see the application send a TCP packet, the OS retries once, a collect of old stale TCP acknowledgements return from the remote - then nothing. Eleven hours later there have been no more TCP retries, no TCP keepalive, no response from the remote, and no TCP stack error from the OS to abort the application block. The host application is still hung, blocking waiting for either a response or socket failure which never come.
So is this a bug in the OS? Does it matter? It is your application and "our" customer who pays the price. For example, Digi had to go through our RealPort driver and literally add an OS timer to abort every TCP socket call if it did not return in 60 seconds. Yes, this sounds like a royal pain but it was the only way to avoid this failure every few weeks when running across cellular IP.
Recommendation: applications must NEVER block on a socket waiting for a response or socket failure. Applications must always use an OS or external timer to abort socket functions that take longer than 1 minute. Sadly, running in non-blocking mode is NOT enough since at times it will be the API call which fails to return regardless of the block/non-block setting. So even using API calls with explicit timeouts is not safe.
Thursday, December 28, 2006
Wednesday, December 20, 2006
IP-Encapsulation of Modbus/RTU
Summary: Modbus/RTU can easily be encapsulated within TCP/IP ... as long as there exists some mechanism to keep full Modbus/RTU messages packed within a single TCP segment or UDP packet.
Most industrial users have learned to be wary of expecting Modbus/RTU to work over error-correcting modems (especially radio) unless you use special modems which are Modbus/RTU aware. So it is wise to be wary of moving Modbus/RTU over IP without some special settings or features in the IP devices involved. Fortunately all Digi devices (and most competitors' devices) have such features or settings.
Bullet-Proof Solution: Modbus Bridges
The safest and most flexible way to move Modbus over IP is to use devices which fully understand the Modbus protocol and dialects of Modbus/TCP, Modbus/RTU, and Modbus/ASCII. This allows multiple Masters to share the slave(s), plus Modbus/TCP masters can query Modbus/RTU slaves and the bridge handles the protocol conversions.
More detailed information of this topic is this application note
Setting up Digi One IAP for Modbus Bridging. The basic information in this application note applies to the following Digi products with Modbus Bridge ability:
- Digi One IA, Digi One IAP
- PortServer TS1 to 4 MEI including TS H MEI(adds Ext Temp -35 to +74DegC), TS Hcc MEI(adds Conformal Coating), and coming soon TS Haz MEI which adds Div 1 Cls II certs
- PortServer TS8 and TS16
- Digi Connect WAN IA)
- (Coming in next firmware release: Digi Connect SP, Wi-SP, ME, Wi-ME, EM, Wi-EM)
Effective Solution: TCP (or UDP) Sockets Profile
If you don't really require the multi-master or protocol bridging features, then any Digi device server can be used. By default the Digi serial "TCP Socket Profile" will break all messages into TCP segments of from 4 to 64 bytes - not what you want for Modbus/RTU. This default behavior creates the lowest latency for normal data without the timing fussiness of Modbus/RTU. However, all you need to do is enable the option checkbox feature "Send data only under any of the following conditions" and then the sub-option "Send after the following number of idle milleseconds". Entering a time such as 25 milliseconds causes the Digi device server to continue collecting data and delays creation of the TCP segment packet until no more serial data is seen for 25 milliseconds. This is a very nice fit to the Modbus/RTU "3.5 character idle time" end-of-message condition. Why not use 5 msec? Well, experience has shown me the 25 (or even 100 msec for cellular) is a more robust value.
So an example solution using TCP Socket Profile would be to use an OPC server such as Kepware which can put most of its serial protocols into a TCP/IP socket. These should naturally put a full Modbus/RTU request into a single TCP segment - the host application is "defective" if it causes more than one TCP segement to be used; it means the host application vendor doesn't know what they are doing. Since the Digi device server receives the entire request as a single TCP segment, the full Modbus/RTU request will move out of the serial port as a single continuous stream of bytes. With the correct settings, when the Modbus/RTU response returns the Digi device server
Friday, December 15, 2006
Mixing Modbus and Rockwell on Ethernet
Both Modbus and PCCC-based protocols like DF1 or CSPv4 (AB/Ethernet) have been around for years. Yet if one looks at the similarities between the two, one quickly sees that the act of reading 10 words from an N7 data file is exactly the same as reading 10 words from Modbus 4x00001. The Digi One IAP leveraged this to become the world's first off-the-shelf transparent protocol bridge. It freely accepts Modbus or Rockwell requests and bridges them to the appropriate form for the slave to understand.
Here is an example system:
- The ControlLogix can poll the Modbus/TCP and DF1 PLC
- The Modbus/TCP PLC can poll the ControlLogix and DF1 PLC
- The DF1 PLC can poll the ControlLogix and Modbus/TCP PLC.
- Modbus/TCP is 001E00000006010100000030
- Modbus/RTU is 0101000000303C1E
- Modbus/ASCII is :010100000030CE(CR)(NL)
- DF1 Full-Duplex is 100201000F000019A206038500001003DE06
- CSPv4 is 0107000E00 … 010500000F000019A2060385000
- PCCC-Ethernet/IP is 6F002800 … 0000010000000F000019A2060385000
The Digi One IAP takes this one step further - since each of these bold, underlines commands is accomplishing the same thing - namely reading the first 48-bits of bit memory - the Digi One IAP can take either command and mechanically create the other. So given the Modbus command 010100000030, it can create the PCCC command 0F000019A20603850000. Given the core PCCC command 0F000019A20603850000 it can create the Modbus command 010100000030. So this how a Modbus/TCP master can query a ControlLogix with PCCC-enabled. the Modbus/TCP master thinks it is polling another Modbus device. The ControlLogix thinks it is being polled by another Ethernet/IP device.
Here are links to other related information:
Digi One IAP product page
Application Note for Modbus master polling Rockwell devices.
Excel spreadsheet for Modbus master polling Rockwell devices.
Application Note for Rockwell master polling Modbus devices.
Excel spreadsheet for Rockwell master polling Modbus devices.
PDF presentation of various ways to mix Modbus and Rockwell devices
Rockwell AB PLC via Cellular
So far we have succeeded in getting several Rockwell/Allen-Bradley PLC up on Cellular with the Digi Connect WAN, which is a cellular router for GSM or CDMA with local Ethernet and serial port.
In Summary:
In Summary:
- Serial DF1: You can access serial MicroLogix PLC such the MicroLogix 1200 on the remote Digi Connect WAN's serial port. You either need to have an OPC server which can directly encapsulate DF1 protocols into TCP/IP or to use Digi RealPort to create redirected COM ports for RSLinx. Ideally, using the newer DF1 Radio Modem protocol can cut your data costs in half, but DF1 Full-Duplex or Half-Duplex can also be used. DH485 won't work via cellular due to the high latency. You must slow the PLC (ACK) timeout setting down to 30 seconds, so you cannot use a MicroLogix 1000 since it doesn't allow this parameter to be adjusted. DF1 Radio Modem has no DF1 (ACK) or (NAK), which is why it costs less to use.
- CSPv4 or AB/Ethernet: You can access legacy PLC such as SLC5/05 and PLC5E by enabling TCP port forwarding of port 2222 on the Digi Connect WAN. Under RSLinx you enter the IP or DNS name for your Digi Connect WAN in the "Ethernet Driver", then right click the driver to slow down the timeouts from default of 3 seconds to a cellular-friendly 30-seconds. For a bit of fun, open this link in your browser and you will access the web pages of my SLC5/05 through Cingular/GSM cellular - http://digiwan.gotdns.org:8080/. But please don't leave this page open since you'll impact other people trying to look at my cellular PLC.
- Ethernet/IP: You can access ControlLogix and other newer PLC supporting Ethernet/IP by enabling TCP port forwarding of port 44818 on the Digi Connect WAN. Under RSLinx you enter the IP or DNS name for your Digi Connect WAN in the "Remote Devices via Linx Gateway" Driver, then right click the driver to slow down the timeouts from default of 3 seconds to a cellular-friendly 30-seconds. You cannot use the RSLinx Ethernet/IP driver since it relies on UDP broadcast which cannot move across wide-area-networks.
If you want more detailed instructions, I have an application note online here:
90000772_A_Cell_AB.pdf
Monday, December 11, 2006
Simulating Multi-drop Across routed IP
Summary: the UDP Sockets profile in Digi device servers can be used to simulate multi-drop behavior in routed IP or wide-area networks. An application note is linked to this entry.
Ever wished your Ethernet could mimic an RS-485 network? Or are you trying to replace an old, expensive multi-point analog modem system with newer IP-based technologies such as cellular, satellite, or aDSL links?
On a local Ethernet subnet a UDP broadcast can be used to simulate multi-drop ... however IT departments and anyone thinking of the future knows IP broadcast is something not to be used lightly. IP broadcast loads every device on the network and examples of high broadcast load killing or crippling important embedded devices are common.
The preferred method on a local Ethernet is the use of Class D IP (aka IP addresses in the 224.x.x.x to 239.x.x.x range). However, details of IP assignment, IP collision, and the risk of turning switches into hubs make this a risky and confusing technology. Most heavy users of ODVA Ethernet/IP can cite a few cases where enabling high multi-cast traffic killed other third-party products (notably security or video devices) which had treated all multicast traffic as broadcast to be examined by software.
Plus we are talking about wide-area-networks and use of cellular or satellite technology. Routed IP networks won't move broadcast or multicast traffic unless active proxies exist at each end to encapsulate the broadcast/multicast traffic into TCP/IP.
Fortunately, the Digi One IAP (and most Digi device servers) include the ability to use a form of repeated UDP/IP unicast to simulate multicast to up to 64 remote peers. I have customers using this to move Modbus/RTU and AB DF1 Half-Duplex through routed private wide-area-network. Here is an application note which explains how to set this up.
(For now it is a Word 2003 document - but it can be opened by Open Office Writer v2.0 if you don't have Word. I'll shortly turn it into a Acrobat PDF)
http://iatips.com/blogimage/90000xxx_A_UDP_Multidrop.doc
Ever wished your Ethernet could mimic an RS-485 network? Or are you trying to replace an old, expensive multi-point analog modem system with newer IP-based technologies such as cellular, satellite, or aDSL links?
On a local Ethernet subnet a UDP broadcast can be used to simulate multi-drop ... however IT departments and anyone thinking of the future knows IP broadcast is something not to be used lightly. IP broadcast loads every device on the network and examples of high broadcast load killing or crippling important embedded devices are common.
The preferred method on a local Ethernet is the use of Class D IP (aka IP addresses in the 224.x.x.x to 239.x.x.x range). However, details of IP assignment, IP collision, and the risk of turning switches into hubs make this a risky and confusing technology. Most heavy users of ODVA Ethernet/IP can cite a few cases where enabling high multi-cast traffic killed other third-party products (notably security or video devices) which had treated all multicast traffic as broadcast to be examined by software.
Plus we are talking about wide-area-networks and use of cellular or satellite technology. Routed IP networks won't move broadcast or multicast traffic unless active proxies exist at each end to encapsulate the broadcast/multicast traffic into TCP/IP.
Fortunately, the Digi One IAP (and most Digi device servers) include the ability to use a form of repeated UDP/IP unicast to simulate multicast to up to 64 remote peers. I have customers using this to move Modbus/RTU and AB DF1 Half-Duplex through routed private wide-area-network. Here is an application note which explains how to set this up.
(For now it is a Word 2003 document - but it can be opened by Open Office Writer v2.0 if you don't have Word. I'll shortly turn it into a Acrobat PDF)
http://iatips.com/blogimage/90000xxx_A_UDP_Multidrop.doc
Thursday, December 07, 2006
Rockwell Protocol Documents
A friend just pointed out this public web page to me: How to Communicate with Rockwell Automation Products. While have seen many of this documents before, a few of them were new for me. It includes information on:
- How to talk to ControlLogix tag data via Ethernet/IP
- How to understand ControlLogix data structure packing when read raw
- The DF1 serial protocol specification
- How to encapsulate CIP over DF1 (ie: talk to serial port of Compact/ControlLogix)
- How to use Ethernet/IP explicit messaging to ControlLogix
- How to use Ethernet/IP I/O messaging with ControlLogix
In addition, I see www.ab.com has added a new DF1 supplement to its Knowledge Base. Since you have to login giving you a direct link is pointless, but it is called "DF1 Protocol supplement 17706516". It compares PLC5 and SLC5 communications, covers some useful commands such as 0x0AB "Protected Typed Logical Write with Mask" to write individual bits, and new data file types not covered in the latest 1996 version of the DF1 specification.
While we are discussing new Rockwell protocol information, you should also review and be aware of the new "DF1 Radio Modem" protocol. I don't think there is a form specification, but you can find a file in the http://www.ab.com/ Knowledge Base that describes the simple differences between it and DF1 Full-Duplex. In summary, DF1 Radio Modem *IS* DF1 Full-Duplex without the protocol ACK/NAK. It is designed for use in radio systems where the powering up of slave modems just to ACK something they will respond to anyway just slows down overall polling. I'm also finding it ideal for cellular IP networks since it literally cuts your data usage by 50 to 60% to NOT be moving 2-byte DF1 ACKs within TCP/IP which also includes a TCP acknowledgements. SInce DF1 includes a TNS or transaction number, there is no problem with mishandling lost or delayed messages.
The main catch today is that I think neither RSLinx nor ControlLogix support DF1 Radio Modem - it is mainly a MicroLogix and SLC5 family resource. However the next release of the Digi One IAP will include the ability to bridge to DF1 Radio Modem from Ethernet/IP, CSPv4 (AB/Ethernet) and DF1 Full-Duplex.
Wednesday, December 06, 2006
Cellular IP-Friendly Apps - It Costs to Talk
Summary: All communication must be "under control". All data sent into the cellular system costs money; even if the remote cellular device is powered off, the customer still pays for data set to it.
As a follow-on to the discussion of Retrying TCP Socket Opens, applications must allow the user to both understand and limit all aspects of protocol usage and retry. Users must be allowed to limit and predict a reasonable worst case traffic cost. For example, some protocols include large blocks of initial connection negotiation, which means talking once per minute over an continuously open socket could result in much less cost than talking once per 10 minutes over a socket opened just for one transaction. I have seen applications that allow users to set a maximum desired retry setting - then not always follow that setting and do retries anyway in certain fault conditions.
Recommendation: application-writers must step back and examine every place within the application they create traffic and confirm users have the ability to limit the traffic created.
Example and Numbers: now most of you will be saying "Yah, dahh - so obvious why is this even mentioned?". Well, I'll give you an all too typical example of how this affects real customers. A customer (call him Joe) running a pilot on cellular data access calls to complain his costs are higher than expected. He says he's just polling 3 Modbus registers every 5 minutes. Being no dummy, Joe has already calculated that each request should be 12 bytes of data (One Modbus/TCP function 3 read) and each response should be 17 bytes of data (One Modbus/TCP response with 4 registers since he is reading 4x00003, 4x00004 and 4x00006 so one assumes 4x00005 comes along for the ride). One poll each 5 minutes works out to be 8640 poll per 30 days, so he had hoped to see only about a quarter-megabyte of traffic a month. Yet Joe was seeing data bill for 6 to 10 MB of traffic a month. This means his $20 per month 5MB plan was costing him closer to $60 per month with data overages.
First, Joe overlooked the fact that he has to pay for not only his Modbus data, but also the TCP and IP overhead used to move it. Standard Windows-generated TCP headers are 20 bytes and so are the IP headers. Linux tends to defaults to use TCP time-stamps and thus creates 28-byte TCP headers. So each request is NOT 12 bytes, but 52-60 bytes ... plus the TCP Acknowledge frame will add an additional 40-48 bytes. Yes, YOU pay for the TCP Acknowledgements as well! With headers and TCP Acknowledgement, his responses will be 97-113 bytes not 17. So right off the bat, I can see that he has been under-estimating his monthly traffic. Since he is using Windows, he should be seeing at least 1.6MB of traffic and never 0.25MB.
So I vist Joe and do a network trace of his OPC server traffic. We see that OPC is issuing 3 Modbus polls every 5 minutes - not 1. Hmmm, of course Joe's first reaction is "Heck no - I'm not polling 3 - just 1" but the proof is there as colored pixels on my notebook display. We decode the polls and see the OPC server is polling 3 blocks of 32-registers each. After decoding the Modbus/TCP bytes we learn the exact registers being polled and Joe eventually discovers why these are being polled:
What has been learned here?
As a follow-on to the discussion of Retrying TCP Socket Opens, applications must allow the user to both understand and limit all aspects of protocol usage and retry. Users must be allowed to limit and predict a reasonable worst case traffic cost. For example, some protocols include large blocks of initial connection negotiation, which means talking once per minute over an continuously open socket could result in much less cost than talking once per 10 minutes over a socket opened just for one transaction. I have seen applications that allow users to set a maximum desired retry setting - then not always follow that setting and do retries anyway in certain fault conditions.
Recommendation: application-writers must step back and examine every place within the application they create traffic and confirm users have the ability to limit the traffic created.
Example and Numbers: now most of you will be saying "Yah, dahh - so obvious why is this even mentioned?". Well, I'll give you an all too typical example of how this affects real customers. A customer (call him Joe) running a pilot on cellular data access calls to complain his costs are higher than expected. He says he's just polling 3 Modbus registers every 5 minutes. Being no dummy, Joe has already calculated that each request should be 12 bytes of data (One Modbus/TCP function 3 read) and each response should be 17 bytes of data (One Modbus/TCP response with 4 registers since he is reading 4x00003, 4x00004 and 4x00006 so one assumes 4x00005 comes along for the ride). One poll each 5 minutes works out to be 8640 poll per 30 days, so he had hoped to see only about a quarter-megabyte of traffic a month. Yet Joe was seeing data bill for 6 to 10 MB of traffic a month. This means his $20 per month 5MB plan was costing him closer to $60 per month with data overages.
First, Joe overlooked the fact that he has to pay for not only his Modbus data, but also the TCP and IP overhead used to move it. Standard Windows-generated TCP headers are 20 bytes and so are the IP headers. Linux tends to defaults to use TCP time-stamps and thus creates 28-byte TCP headers. So each request is NOT 12 bytes, but 52-60 bytes ... plus the TCP Acknowledge frame will add an additional 40-48 bytes. Yes, YOU pay for the TCP Acknowledgements as well! With headers and TCP Acknowledgement, his responses will be 97-113 bytes not 17. So right off the bat, I can see that he has been under-estimating his monthly traffic. Since he is using Windows, he should be seeing at least 1.6MB of traffic and never 0.25MB.
So I vist Joe and do a network trace of his OPC server traffic. We see that OPC is issuing 3 Modbus polls every 5 minutes - not 1. Hmmm, of course Joe's first reaction is "Heck no - I'm not polling 3 - just 1" but the proof is there as colored pixels on my notebook display. We decode the polls and see the OPC server is polling 3 blocks of 32-registers each. After decoding the Modbus/TCP bytes we learn the exact registers being polled and Joe eventually discovers why these are being polled:
- One block of 32 registers is fetching his 3 desired value of 4x00003, 4x00004 and 4x00006. Reading the fine print in the OPC manual we see that the OPC server decided this was a "scattered poll" of 2 separate memory areas so it bumped the size up to 32 registers. So just for this one poll, his monthly budget is up to 2.8MB instead of 0.25MB
- A second block was caused by Joe programming an HMI display to pop-up if a certain alarm condition where true in the field. This was a demo he'd done to impress a customer, but Joe hadn't thought to disable it nor had realized the exact "cost" of such a feature. So the OPC server needs a single register off somewhere else in the PLC memory to satisfy the HMI's alarm/event function. We don't know why this is polled as 32 registers instead of 1 - it is not a "scattered poll" as defined by the OPC vendor's documentation. Perhaps his HMI or OPC server software has a bug in it. Since this is Modbus/TCP (not serial) it is unlikely anyone else has noticed or cared that the application is moving 62 bytes of extra data in every poll. After all, Ethernet is fast and costs nothing to use. It is possible the programmers at the OPC vendor just decided there was no reason to ever poll less than 32 registers when using fast, free "Ethernet".
- The final block was being caused by Joe's boss leaving open an HMI display in another room that wasn't supposed to be left open - human error (or is it?). Joe learned instanty how important it was for him to properly configure the HMI display settings which timed out displays - either closing the window or just stopping the supporting data polls. He had done that for the normal "user display", but had been lazy and not put such settings into the various diagnostic displays users weren't expected to use!
What has been learned here?
- With the overhead of TCP/IP, Joe learned that he had to pay for over 4 times more traffic than his raw Modbus byte calculates had led him to believe.
- Joe learned that he should be looking at using UDP/IP instead of TCP/IP for his Modbus/TCP since this would cut 40-60% off his bill instantly. Modbus doesn't really require the TCP Acknowledgement and my own tests of UDP/IP over cellular shows it to be about 99.99% reliable - or put another way, I only see about 1 packet lost per 10,000 sent.
- Joe learned how to review his OPC server's data statistics page. His OPC server had been (indirectly) giving him the answer as to why his data usage was so high. While his OPC server never totaled up the data bytes to include TCP/IP overhead, it was able to show him the 36 polls per hour he was moving instead of his expected 12 (one per 5 minutes).
- Joe learned that perhaps he needs to look for a new OPC supplier, since his present vendor just doesn't seem to see the big picture of IP-enabled protocols; that Ethernet is not the only media using TCP/IP. Increasingly people expect TCP/IP to move through diverse media which is not always "fast and free" like Ethernet. Joe's present OPC supplier didn't give him the ability to reduce the poll block size below 32 registers when the OPC system thought "Ethernet" was being used.
- Joe learned he had to be more aggressive in his HMI display design. He couldn't assume users would only look at certain displays and not leave open displays unexpectedly. Joe needed to actively set every possible display to automatically close or stop generating new polls. In fact, after review he discovered that most of his displays had no need for "real-time" update and he could just set them to display the data once as read without any refresh. Users always had to the option to manually redisplay the page.
- Joe learned that maybe just reading data from the RTU program directly was not such a wise idea. His RTU had the ability to copy and repack data into special polling areas to eliminate "scattered polls". In fact, in the above example we traced at Joe's site, all of the data in those 3 polls could have easily fit within a single 13 register block. So Joe is reviewing his RTU program design to repack ALL data of interest - even data supporting rare HMI displays - into a dedicated memory area. While Joe had previously hoped to avoid this work, he now sees the potential dollar saving or cost penalty his company could face if he avoided this work.
So really in summary I have to say Your data polling needs to be UNDER CONTROL, as in being controlled. You need both the tools and the investment in effort to define as exactly as possible each and every data poll.
Friday, November 17, 2006
TCP/IP Encapsulation Limited by Distance?
Summary: serial tunneling or TCP encapsulation is NOT directly affected by distance. However, it is affected by "hops" or how many routers and segments it goes through. To reduce the effect "hops" have on your TCP/IP Encapsulation, you need to set the correct options in your Digi Device Server. These are NOT standard defaults since what works best for Wide-Area-Network is not best for local direct Ethernet links.
What is serial TCP/IP encapsulation? It is also called serial bridging or serial tunneling. Think of it as the modern IP equivalent to old short-haul modems or leased line modems. At each end you have a "modem", you connect a serial cable to each, and you create a virtual serial link running from end to end.

During a webinar I gave, a traffic-industry user asked if serial TCP encapsulation is limited by distance. If he serial bridges between 2 intersections of a road, things work fine. However, if he tries the same serial bridge between an intersection and the home office, then serial bridging does NOT work. So he was wondering "what is the distance limit for serial bridging or encapsulation?"
The simple answer is "There is no distance limitation". However, the longer the distance you move your serial encapsulation, the more routers and network segments (hops) your traffic moves through. The more hops your traffic moves through, the more variable latency (or delay or jitter) is introduced between consecutive network packets. This affects the timing and different protocols and software implementations react differently to it.
Let me just throw some hypothetical numbers together. Let's say the device sends data as a block of 100 bytes; the receiving device will loop and collect this data. Of course the receiving device cannot just wait for 100 bytes - what if the line breaks? It could sit there forever waiting for the end of the message. So various timers are coded to enable the receiving device to understand failure and abort receiving. Let's say the receiving device waits at most 20 milliseconds for the next byte. On a direct serial link this is very common - once the sending device starts sending data it is very unlikely that even a 2 or 3 millisecond gap will appear between bytes.
Enter serial encapsulation - either by radio or Ethernet or any IP-based media. All of these technologies are packet-based and most include some form of error-retry. So now the serial bytes collect in a buffer up to some point, then a chunk of them move together as one packet. Ideally, the full message moves as a single packet. However, if the message becomes split between 2 or more packets it is possible a gap will be detected by the receiving device. So for illustration we'll say the 100 bytes is split into 4 x 25-byte packets. On a single-hop network, there is much less opportunity for timing delays to open gaps in the final serial data. This diagram shows a small gap between the 25th and 26th bytes:

But running the serial encapsulation through many network hops greatly increases the accumulated delays added to each packet. So each hop has the opportunity to increase the latency and lag. This diagram shows a much larger gaps that may occur when the packets create the serial traffic at the remote end:

How to solve this problem? On the Digi Connect products, you'll be using one of these serial port profiles: TCP Sockets or Serial Bridge. Under the Advanced Serial Settings you need to enable the check box labeled: [ ] Send data only under any of the following conditions. If you do not check this option, the Digi Device Server purposely fragments the serial data into many TCP segments to provide more realistic end-to-end performance on direct Ethernet links. However, since you want to move data through a wide-area network, you are less concerned with raw throughput than in preventing message fragmentation. You may also be interested in creating fewer TCP/IP packets to send more serial data. Changing this setting accomplishes both of these things.
You now have 2 options to define when TCP packets are moved:
What is serial TCP/IP encapsulation? It is also called serial bridging or serial tunneling. Think of it as the modern IP equivalent to old short-haul modems or leased line modems. At each end you have a "modem", you connect a serial cable to each, and you create a virtual serial link running from end to end.
During a webinar I gave, a traffic-industry user asked if serial TCP encapsulation is limited by distance. If he serial bridges between 2 intersections of a road, things work fine. However, if he tries the same serial bridge between an intersection and the home office, then serial bridging does NOT work. So he was wondering "what is the distance limit for serial bridging or encapsulation?"
The simple answer is "There is no distance limitation". However, the longer the distance you move your serial encapsulation, the more routers and network segments (hops) your traffic moves through. The more hops your traffic moves through, the more variable latency (or delay or jitter) is introduced between consecutive network packets. This affects the timing and different protocols and software implementations react differently to it.
Let me just throw some hypothetical numbers together. Let's say the device sends data as a block of 100 bytes; the receiving device will loop and collect this data. Of course the receiving device cannot just wait for 100 bytes - what if the line breaks? It could sit there forever waiting for the end of the message. So various timers are coded to enable the receiving device to understand failure and abort receiving. Let's say the receiving device waits at most 20 milliseconds for the next byte. On a direct serial link this is very common - once the sending device starts sending data it is very unlikely that even a 2 or 3 millisecond gap will appear between bytes.
Enter serial encapsulation - either by radio or Ethernet or any IP-based media. All of these technologies are packet-based and most include some form of error-retry. So now the serial bytes collect in a buffer up to some point, then a chunk of them move together as one packet. Ideally, the full message moves as a single packet. However, if the message becomes split between 2 or more packets it is possible a gap will be detected by the receiving device. So for illustration we'll say the 100 bytes is split into 4 x 25-byte packets. On a single-hop network, there is much less opportunity for timing delays to open gaps in the final serial data. This diagram shows a small gap between the 25th and 26th bytes:
But running the serial encapsulation through many network hops greatly increases the accumulated delays added to each packet. So each hop has the opportunity to increase the latency and lag. This diagram shows a much larger gaps that may occur when the packets create the serial traffic at the remote end:
How to solve this problem? On the Digi Connect products, you'll be using one of these serial port profiles: TCP Sockets or Serial Bridge. Under the Advanced Serial Settings you need to enable the check box labeled: [ ] Send data only under any of the following conditions. If you do not check this option, the Digi Device Server purposely fragments the serial data into many TCP segments to provide more realistic end-to-end performance on direct Ethernet links. However, since you want to move data through a wide-area network, you are less concerned with raw throughput than in preventing message fragmentation. You may also be interested in creating fewer TCP/IP packets to send more serial data. Changing this setting accomplishes both of these things.
You now have 2 options to define when TCP packets are moved:
- "Send when data is present on the serial line" allows you to define an end-of-message pattern such as a carriage-return (\r or \r\n, etc).
- "Send after the following number of idle milliseconds" allows you to define an idle or quiet time to wait before sending data. This second option is generally safest and I find a value of 10 or 25 milliseconds to be ideal with most automated devices.
Note: do NOT change the setting in the "Send after the following number of bytes" field! This is rarely useful and it does NOT mean (when unchecked) that the Digi Device Server must see 1024 bytes before it sends anything. I have had too many users change this to 1 and then wonder why they have a huge amount of network traffic!
Friday, November 10, 2006
Application Pitfalls: Serial DF1 over WAN
Digi's wireless group was asking me why AB/DF1 didn't always work over radio when per the specification, DF1 has a nice end-of-message pattern. One would think moving serial DF1 through radio or cellular-IP would be natural and painless.
However, the problem I see watching Windows applications use the serial API (via the PortMon utility) is that they ASSUME a small delay or gap between the (DLE)(ACK) bytes and the response from the slave.
So the application uses the incorrect algorithm:
The correct algorithm would be:
See Also:
However, the problem I see watching Windows applications use the serial API (via the PortMon utility) is that they ASSUME a small delay or gap between the (DLE)(ACK) bytes and the response from the slave.
So the application uses the incorrect algorithm:
- Read 2 Bytes
- Ask Windows to notify application when more data comes
- Loop, reading buffered data and waiting until full response seen
The correct algorithm would be:
- Read 2 Bytes
- Loop, reading buffered data and waiting until full response seen
See Also:
- Download the Rockwell Allen-Bradley DF1 specification: this used to be open to download as a PDF ... it is still free but now you need to log into http://www.ab.com/ and find "DF1 Protocol and Command Set Reference Manual - Publication 1770-6.5.16"
- Download PortMon http://www.microsoft.com/technet/sysinternals/utilities/PortMon.mspx
Thursday, November 09, 2006
City-wide WiFi - it's not Ethernet
One of my customers is struggling to IP-enable a few dozen Ethernet PLC via one of these new fangled city-wide WiFi systems that are all the rage now. Looked good on paper, but they can only keep the PLCs online for about 20 minutes at a time.
Why? Is the WiFi system defective? Of course not ... it is just behaving more like Wide-Area-Network than Local-Area-Network. I am not directly involved in this, but I'd wager the problem is neither the WiFi nor the PLC. The problem is the host software making Ethenet LAN assumptions about the system. I should offer to go out and do some latency tests; I'd wager the system has high and variable latency more like satellite or cellular.
So industrial control application developers beware, migrating your Ethernet-enabled, LAN-friendly applications to be true IP-enabled, WAN-friendly applications will become more important every time another city annouces the installation of a city-wide wireless infrastructure.
Why? Is the WiFi system defective? Of course not ... it is just behaving more like Wide-Area-Network than Local-Area-Network. I am not directly involved in this, but I'd wager the problem is neither the WiFi nor the PLC. The problem is the host software making Ethenet LAN assumptions about the system. I should offer to go out and do some latency tests; I'd wager the system has high and variable latency more like satellite or cellular.
So industrial control application developers beware, migrating your Ethernet-enabled, LAN-friendly applications to be true IP-enabled, WAN-friendly applications will become more important every time another city annouces the installation of a city-wide wireless infrastructure.
Monday, November 06, 2006
Cellular-IP Friendly Apps - Retrying Socket Opens
Most industrial applications allow the user to set a slow poll rate – such as one poll per 5 minutes. This allows a user to budget a cell plan at 5MB per month and be quite assured of not going over. Unfortunately, this steady-state poll rate is unrelated to initial TCP/IP socket connection opens!
If the remote device is powered down or the TCP socket open fails for any reason, most applications will attempt to reopen the TCP socket continuously. On Ethernet this may make sense; the more frequently the open is retried, the sooner the failed connection will recover. Most Ethernet-based applications will retry opening a TCP socket every 5 to 30 seconds forever. However, for cellular you are paying for all traffic entering the cellular system. It is not Cingular or Sprint or Verizon's fault your remote device is off-line. You will be billed for each and every TCP retry. I have literally seen applications create up to 1000 MB of traffic each day attempting to reopen a TCP socket to an unreachable remote IP. On a 5 MB per month plan, this 1GB of overage could easily cost you $1000 or more for the month!
Recommendation: all applications must include a user-settable option to delay attempts to reopen TCP sockets. This value can default to no-delay, but users must be able to set a delay of at least 1 hour between retries. This enables the user to define and stay within their data usage budget regardless of success or failure of the TCP connection.
Impact: On Ethernet this should have no direct consequences since the recommended default is no delay. Cellular users must adjust this retry delay to match their data traffic expectations and their cell plan budget.
For example, an application polling 10 Modbus registers per 5 minutes via TCP/IP creates about 198 bytes per poll. This works out to 2376 bytes per hour or a little under 2 MB per month. This is a very safe poll rate when paying for a 5 MB per month plan.
Therefore the desired TCP reconnect scenario should also create no more than 2400 bytes per hour. Consider that a 20-second timeout under Windows creates at least 120 bytes of traffic to an off-line remote. Windows sends a 40-byte [SYN] packet and retries the same 40-byte [SYN] in roughly 3 and then 8 seconds from the previous [SYN] packet. Increasing the timeout to 30 or more seconds creates a fourth 40-byte [SYN] packet sent about 18 seconds after the third. So forcing an application to only attempt one connection per 5 minutes will create from 1440 to 1920 bytes of traffic per hour. This will not break our budgeted cell plan.
If the remote device is powered down or the TCP socket open fails for any reason, most applications will attempt to reopen the TCP socket continuously. On Ethernet this may make sense; the more frequently the open is retried, the sooner the failed connection will recover. Most Ethernet-based applications will retry opening a TCP socket every 5 to 30 seconds forever. However, for cellular you are paying for all traffic entering the cellular system. It is not Cingular or Sprint or Verizon's fault your remote device is off-line. You will be billed for each and every TCP retry. I have literally seen applications create up to 1000 MB of traffic each day attempting to reopen a TCP socket to an unreachable remote IP. On a 5 MB per month plan, this 1GB of overage could easily cost you $1000 or more for the month!
Recommendation: all applications must include a user-settable option to delay attempts to reopen TCP sockets. This value can default to no-delay, but users must be able to set a delay of at least 1 hour between retries. This enables the user to define and stay within their data usage budget regardless of success or failure of the TCP connection.
Impact: On Ethernet this should have no direct consequences since the recommended default is no delay. Cellular users must adjust this retry delay to match their data traffic expectations and their cell plan budget.
For example, an application polling 10 Modbus registers per 5 minutes via TCP/IP creates about 198 bytes per poll. This works out to 2376 bytes per hour or a little under 2 MB per month. This is a very safe poll rate when paying for a 5 MB per month plan.
Therefore the desired TCP reconnect scenario should also create no more than 2400 bytes per hour. Consider that a 20-second timeout under Windows creates at least 120 bytes of traffic to an off-line remote. Windows sends a 40-byte [SYN] packet and retries the same 40-byte [SYN] in roughly 3 and then 8 seconds from the previous [SYN] packet. Increasing the timeout to 30 or more seconds creates a fourth 40-byte [SYN] packet sent about 18 seconds after the third. So forcing an application to only attempt one connection per 5 minutes will create from 1440 to 1920 bytes of traffic per hour. This will not break our budgeted cell plan.
Tuesday, October 31, 2006
Modbus Bid Spec Suggestions
A large customer asked me for advice on bid-specing the use of Modbus/TCP. They are expecting HVAC and other non-production systems to provide "gateways" with Modbus/TCP to simplify central HMI and data collection. Experienced field people know this is not quite as easy as it sounds.
So I stepped back and put myself in their shoes - if I were trying to design a new assembly plant and I hoped to monitor HVAC, chemical tank farm, and such by Modbus/TCP, then what issues would hinder this? What details NOT included in the http://www.modbus-ida.org/ protocol specification would complicate true interoperability? I have many experiences of integration problems with Modbus masters and slaves from 2 different vendors not quite talking as expected. Usually the customer ends up PAYING one vendor or the other to change; or the customer has to buy a 3rd party box to fix the difference of opinion.
So I stepped back and put myself in their shoes - if I were trying to design a new assembly plant and I hoped to monitor HVAC, chemical tank farm, and such by Modbus/TCP, then what issues would hinder this? What details NOT included in the http://www.modbus-ida.org/ protocol specification would complicate true interoperability? I have many experiences of integration problems with Modbus masters and slaves from 2 different vendors not quite talking as expected. Usually the customer ends up PAYING one vendor or the other to change; or the customer has to buy a 3rd party box to fix the difference of opinion.
So how to avoid this up front? Here is the list I created:
- The required interface is Modbus/TCP running on standard Ethernet II frames and following the published specification at http://www.modbus-ida.org/.
- All devices must support at least 100M half-duplex Ethernet and if auto-negotiate is supported, they must be manually configurable to force 100M Half-Duplex.
- If the supplied product uses serial Modbus/RTU or Modbus/ASCII, then vendor must supply a configured, tested, and powered Modbus Ethernet-to-Serial bridge (such as the Digi One IA, model 70001862) to bridge this to Modbus/TCP on Ethernet.
- All data must be available and/or mirrored within the Modbus 4x or "Holding Register" memory area. The other areas can be optionally supported, but all 0x, 1x, and 3x data must be readable in the 4x memory area. For digital writes, support of single-bit writes (function 5) to the 0x area are acceptable. Products that require access to the 1x and 3x area to operate are not acceptable; access to 1x/3x area must be optional.
- Modbus 32-bit longs and floating points must be available in Modicon 984 Compatibility format, which means as two consecutive 16-bit big-endian registers, with the low word in the first register. Other forms (Daniels/Enron or high-word first) can exist but must be optional.
- All gateways or converters bridging non-Modbus data to Modbus must not provide stale data and must not require special "status registers" be monitored to confirm data validity. If the source device of the non-Modbus data is unavailable or the data is out-of-date, then Modbus/TCP requests must return an exception such as 0x0B until the source data is valid again.
- Register 4x00001 must exist and be readable to allow simple, predictable "comm tests".
- Software tools must function properly with slaves only supporting Modbus functions 3 and 16. Requiring diagnostic function 8 support is not acceptable.
- Software tools must be configurable to write a single register as either function 6 or 16.
- Software tools must be configurable to limit reads and write to user selectable limits; for example, the software must accept being limited to reading 1 register per transaction and writing 1 register per transaction.
- Software tools must allow setting to the Modbus/TCP "Unit Id" to a value other than zero. This is required for Ethernet-to-Serial bridging.
- Software tools must use the Modbus/TCP sequence number and modify it between polls. The tool must not leave it set as 0 or 1 all the time.
- To support future wide-area-network usage, all "Masters" must permit TCP socket opens to take up to 30 seconds.
- To support future wide-area-network usage, all "Masters" must permit slave timeouts be set to at least 30 seconds.
- To support future wide-area-network usage, all serial slave devices must have a configurable "gap" or intercharecter delay timeout. The Modbus spec's "3.5 character times" is problematic when dealing with radio & other error-correcting media.
- All devices must be capable of transport via wireless bridging by common Ethernet radio systems such as 802.11 bridges and more traditional 900Mhz line-of-sight bridges.
Now, will all vendors be able to meet all of these requirements? Probably not since many of them are not required per the Modbus-IDA specifications. However, at least this brings the issues up front to be addressed during the bid award phase. If custom firmware modifications are required, it can be addressed up front and not during factory acceptance testing.
Monday, October 23, 2006
Cellular-IP Friendly Apps - Socket Open
Most applications attempt to open a TCP socket using the OS/Windows default timeout. This results in an unpredictable timeout. I looked through Microsoft's VS.NET documentation looking for the "How long?" answer ... and never found an answer. I suspect it depends on your version and service-pack levels. I did a web search to discover the truth and found people claiming Windows timed out in 2 seconds, 5 seconds, 10 seconds, 20 seconds, 20-30 seconds, and even one claiming 5 minutes. Sadly, most of these people were looking for a way to force Windows to use a connection timeout of 1 second or less - which will prevent their applications from working on normal wide-area networks.
Such short connection attempts are not suitable for cellular network where the first response packet from an idle remote tends to complete in 3-4 seconds during average conditions. Therefore even a 5 second timeout is too close to the norm to be suitable.
Recommendation: all applications must use an explicit, predictable timeout during a TCP socket open request. This value can be user-settable higher or lower, but for cellular should default to 20 seconds and be settable to at least 60 seconds for satellite.
Impact: On Ethernet this should have limited direct consequences since the timeout only has affect if the remote is not available. If having your application wait 20 seconds for an inaccessable remote is a problem, then enable a user setting to select either "local-area-network" or "wide-area-network" mode and adjust the default connection timeout as appropriate.
In a best case scenario, failing to wait long enough to open a TCP socket when the network is sluggish could prevent connecting for many minutes as sockets succeed to open, but the OS aborts the open before the successful response can come back from the remote. Keep in mind that over cellular the end user is paying for at least 120 bytes of data for every open attempt, and that TCP retransmissions likely make this 160 or 200 bytes.
In a worst case scenario, this aborting of opened sockets on a remote with limited resources risks tying up all resources with past failed opens. Remember, just because your OS timed out the open does not mean the remote device didn't allocate the connection resource and send a successful response. The lack of resources blocks new attempts by the application to reconnect until TCP keepalive or some other mechanism detects the broken sockets and frees up the resources.
Be warned that under cellular - as if in defiance of traditional faith in the reliability of the TCP state machine - TCP sockets break in rare occasions in ways that common OS will fail to detect! During cellular network hiccups, I have seen machines "hang" for 11 hours waiting for a TCP Acknowledgement that never comes! This is with TCP Keepalive enabled for 5 minutes even.
Some Visual Studio discussion: Just out of curiosity, I did some snooping around inside the Visual Studio .NET documentation. I didn't find a good answer, so cannot explain how to solve this problem.
Here is example VB.NET code to opean a TCP socket:
The only wait to define a predictable TCP socket connection timeout appears to be use an asynchronous design with BeginConnect and some form of external timer to call EndConnect at the desired timeout.
To rephrase myself, I am not saying the default Windows connection timeout is incorrect - I am saying evidence is that you cannot predict what timeout your customer will see if you don't explicitly define one. So while your application running on your computer may default to a nice 20 seconds timeout, what happens if your customer runs the same application on an older computer and sees a 3 second or 5 second timeout? The answer is they won't be able to reliably connect to cellular or satellite remote IPs, and either won't buy your product again or will call Tech Support.
Such short connection attempts are not suitable for cellular network where the first response packet from an idle remote tends to complete in 3-4 seconds during average conditions. Therefore even a 5 second timeout is too close to the norm to be suitable.
Recommendation: all applications must use an explicit, predictable timeout during a TCP socket open request. This value can be user-settable higher or lower, but for cellular should default to 20 seconds and be settable to at least 60 seconds for satellite.
Impact: On Ethernet this should have limited direct consequences since the timeout only has affect if the remote is not available. If having your application wait 20 seconds for an inaccessable remote is a problem, then enable a user setting to select either "local-area-network" or "wide-area-network" mode and adjust the default connection timeout as appropriate.
In a best case scenario, failing to wait long enough to open a TCP socket when the network is sluggish could prevent connecting for many minutes as sockets succeed to open, but the OS aborts the open before the successful response can come back from the remote. Keep in mind that over cellular the end user is paying for at least 120 bytes of data for every open attempt, and that TCP retransmissions likely make this 160 or 200 bytes.
In a worst case scenario, this aborting of opened sockets on a remote with limited resources risks tying up all resources with past failed opens. Remember, just because your OS timed out the open does not mean the remote device didn't allocate the connection resource and send a successful response. The lack of resources blocks new attempts by the application to reconnect until TCP keepalive or some other mechanism detects the broken sockets and frees up the resources.
Be warned that under cellular - as if in defiance of traditional faith in the reliability of the TCP state machine - TCP sockets break in rare occasions in ways that common OS will fail to detect! During cellular network hiccups, I have seen machines "hang" for 11 hours waiting for a TCP Acknowledgement that never comes! This is with TCP Keepalive enabled for 5 minutes even.
Some Visual Studio discussion: Just out of curiosity, I did some snooping around inside the Visual Studio .NET documentation. I didn't find a good answer, so cannot explain how to solve this problem.
Here is example VB.NET code to opean a TCP socket:
- Dim tcpClient As New TcpClient
- Dim ipAddress As IPAddress = dns.GetHostEntry("www.digi.com").AddressList(0)
- TcpClient.Connect(ipAddress, 11003)
The only wait to define a predictable TCP socket connection timeout appears to be use an asynchronous design with BeginConnect and some form of external timer to call EndConnect at the desired timeout.
To rephrase myself, I am not saying the default Windows connection timeout is incorrect - I am saying evidence is that you cannot predict what timeout your customer will see if you don't explicitly define one. So while your application running on your computer may default to a nice 20 seconds timeout, what happens if your customer runs the same application on an older computer and sees a 3 second or 5 second timeout? The answer is they won't be able to reliably connect to cellular or satellite remote IPs, and either won't buy your product again or will call Tech Support.
Friday, October 20, 2006
Cellular-IP Friendly Applications - Intro
In theory, host applications using TCP/IP on Ethernet should work over wide-area networks which support TCP/IP. Unfortunately, most host applications are written and tested for Ethernet, not generic IP. When you move into cellular IP or satellite, the high and variable latency introduced causes many host applications to either fail or generate an order of magnitute more traffic than than they should.
For example, here is a chart of 1000 Modbus/RTU polls over cellular TCP/IP. There is a random delay between polls of 30 seconds to 30 minutes. The patterns are rather striking: most polls complete in between 1 to 2 seconds, but there is clearly some systematic "aliasing" causing responses to complete in 2.8, 3.8, and 10.8 seconds.
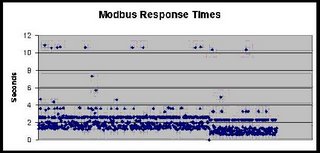
After years of troubleshooting customers systems, I have been creating a running document and commentary on Bad things host apps do. I will be publishing these things over time in this blog. But to summarize:
For example, here is a chart of 1000 Modbus/RTU polls over cellular TCP/IP. There is a random delay between polls of 30 seconds to 30 minutes. The patterns are rather striking: most polls complete in between 1 to 2 seconds, but there is clearly some systematic "aliasing" causing responses to complete in 2.8, 3.8, and 10.8 seconds.
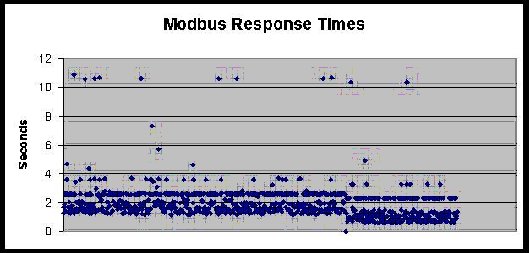
After years of troubleshooting customers systems, I have been creating a running document and commentary on Bad things host apps do. I will be publishing these things over time in this blog. But to summarize:
- The default OS timeout on opening TCP Sockets may be too short.
- Attempting to open TCP sockets to unresponsive remotes must be a controlled process, since retries cost money.
- Since all packets and retries cost money, all aspects of the implemented protocol must be controlled and adjustable.
- OS stack calls may not return if the OS fails to detect a response or socket failure.
- Responses from the remote could take 15 to 60 seconds.
- TCP segment fragmentation and reassembly is exaggerated; can have many seconds of delay between fragments.
- TCP sockets idle longer than 5 minutes often go away without error or detection.
- Every byte your application sends (or resends) costs your customer money.
Thursday, October 12, 2006
Siemens PLC via Cellular
We succeeded in getting a Siemens S7-226 with CP243 and PPI serial up on the Digi Connect WAN, which is a cellular router for GSM or CDMA with local Ethernet and serial port.
In Summary:
In Summary:
- To talk to S7-226 by serial PPI, you need a newer Siemens PC-to-PPI cable - the older one doesn't work. I am not sure why, but that is what we found. Using Digi RealPort we enabled a redirected COM port to the remote Digi Connect WAN's serial port, which is connected to the PPI port of the S7-200. We then defined a radio modem port within MicroWin using that COM port. Although a 30 second timeout would be ideal, MicroWin only gives options for 1, 10 or 100 seconds of timeout. You should probably select the 100 seconds to minimize your comm costs. Now MicroWin or Step7 can freely connect to and reprogram the S7-200. The high end-to-end latency of the cellular IP networks makes the performance pretty sluggish when compared to direct serial, but it works.
- To talk to S7-315 by serial MPI, you need the special Siemens PC-to-MPI cable. Just as with the S7-200, we set up a redirected Digi RealPort, however we did NOT need to fool Step7 into thinking this was a radio modem. It just worked fine as is when given longer timeout settings.
- To talk to CP243 by S7 protocol over ISODE on Ethernet, we enabled TCP port forwarding of port 102 on the Digi Connect WAN to the CP243 module. The CP243 is configured to treat the Digi Connect WAN as its Gateway IP. This also worked fine as is when given longer timeout settings.
Monday, October 09, 2006
Using Python to query Modbus slaves
I use Python ( http://www.python.org/ ) at lot in my testing. It is a language designed to make a programmer's life easy and the computer sweat - in other words, it is an ideal tool for test scripts and maybe a bad tool for "constant use" tools.
Stock python has no serial support. For serial, you'll need some serial tool like pyserial - this hides details of OS and allows Linux (or Windows) style serial calls on either OS. A web search of pyserial will turn up a download site - such as http://pyserial.sourceforge.net/ . The "Vaults of parnassus" is another nice source for Python tools including pyserial. http://py.vaults.ca/~x/parnassus/apyllo.py/
Creating binary messages is not hard in Python, but a bit ugly. You use lots of "chr(x)" function to build up a binary string and to parse a binary response lots of "ord()". Other than that, look at the spec at http://www.blogger.com/www.modus-ida.org for details of the actual protocol.
CRC-16 for Modbus (or DF1):
Here is my CRC16 routine including a few test cases (written with no regard for CPU speed, since that is not why one uses Python).
crc16.py as a ZIP file
Stock python has no serial support. For serial, you'll need some serial tool like pyserial - this hides details of OS and allows Linux (or Windows) style serial calls on either OS. A web search of pyserial will turn up a download site - such as http://pyserial.sourceforge.net/ . The "Vaults of parnassus" is another nice source for Python tools including pyserial. http://py.vaults.ca/~x/parnassus/apyllo.py/
Creating binary messages is not hard in Python, but a bit ugly. You use lots of "chr(x)" function to build up a binary string and to parse a binary response lots of "ord()". Other than that, look at the spec at http://www.blogger.com/www.modus-ida.org for details of the actual protocol.
CRC-16 for Modbus (or DF1):
Here is my CRC16 routine including a few test cases (written with no regard for CPU speed, since that is not why one uses Python).
crc16.py as a ZIP file
Friday, October 06, 2006
Better not try to use "unlimited data"
When a potential customer starts talking to me about cellular data access to their telemetry devices, I start the discussion with the basic monthly costs of cellular data. Business cellular plans make you pay for what you use; every byte you send potentially costs you many. Of course, the natural reaction from potential customers is "Oh, that's no problem ... I'll just sign up for one of those 'unlimited plans' I see advertised all the time". When I point out these plans are available only for consumers, the natural reaction is to say "Oh, I just won't tell them this is for business ..."
I'll put on hold a moment the debate of "do unlimited data plans really exist?" and get back to cellular data access to telemetry devices. Today (and perhaps forever) cellular data access only makes sense if you have your data access well defined and under-control. If you poll X words of data every Y minutes, you will be able to select a monthly data plan that fits within a planned budget. If you connect to remote equipment for limited diagnostic maintenance and you understand that the cellular overage charges could cost you X dollars per hour, you will be able to manage your monthly bills. However, if you approach cellular data access to telemetry devices by saying you need to poll as much data as fast as you can, then this is NOT the correct technology for you. You are better to look at the various long-range Ethernet line-of-sight radios.
So back to the question of "do unlimited data plans really exist?" Hmm, unlimited - sounds nice, doesn't it. Yet an Internet search for "+unlimited +internet +cancelled" shows a growing collection of frustrated people with DSL or cable broadband, wireless PDAs, voice-over-ip (VoIP), and cellular plans who have had their "unlimited services" cancelled because they (ta-da) moved too much data. It seems unlimited doesn't really mean unlimited. I could provide links to such information, but the sites tends to be full of wild ranting language, plus I don't want to single out just a few companies. Do the search above and you'll find examples for any type of service you desire.
While I can empathize with the ranters who've found out that unlimited just means "without a predefined limit", as a network professional I understand the basis for these service cancellations. It would be nice if the marketing hype-sters could be honest enough to stop using the term "unlimited", but then no user would sign up for an honest broadband service stupid enough to define limits when competitors are shouting about "unlimited plans".
All IP-based broadband systems consist of a series of hops or links, each with a predefined maximum data throughput. All commercial broadband services try to handle as many customers as they can sign up. Therefore the performance a user sees is merely a function of how many other users are active at that instant, how much data they are trying to push through at that instant, and what is the limiting throughput of the system bottlenecks. As a business person seeking to make money, would you prefer to keep 100 users paying $80 monthly to each move 100MB of data per month (10,000MB/month), or prefer to keep the one user paying $80 monthly to move 10GB (10,000MB) of data per month? While this is an extreme example, as soon as a few of the 100MB/month users complain to the broadband service about their high-speed internet seeming pretty slow speed, the solution is obvious to the business-minded. Canceling the "unlimited service" of the one user moving 10,000MB/month will effectively double the performance of the other 100 users with no added expenses and a mere loss of $80 per month of income. Failing to cancel the "unlimited service" of the one heavy user risks causing 10 or 20 of the other 100 light users to change services with a potential monthly income loss of hundreds or even thousands of dollars. I am not saying this is honest to cancel "unlimited service" based on high usage. I am just saying it is understandable and makes business sense.
How is this cancellation legal? Easy - just read the huge terms of service contract you agree to when you sign up for unlimited data service. To generalize some typical clauses in an unlimited cellular service plan:
I'll put on hold a moment the debate of "do unlimited data plans really exist?" and get back to cellular data access to telemetry devices. Today (and perhaps forever) cellular data access only makes sense if you have your data access well defined and under-control. If you poll X words of data every Y minutes, you will be able to select a monthly data plan that fits within a planned budget. If you connect to remote equipment for limited diagnostic maintenance and you understand that the cellular overage charges could cost you X dollars per hour, you will be able to manage your monthly bills. However, if you approach cellular data access to telemetry devices by saying you need to poll as much data as fast as you can, then this is NOT the correct technology for you. You are better to look at the various long-range Ethernet line-of-sight radios.
So back to the question of "do unlimited data plans really exist?" Hmm, unlimited - sounds nice, doesn't it. Yet an Internet search for "+unlimited +internet +cancelled" shows a growing collection of frustrated people with DSL or cable broadband, wireless PDAs, voice-over-ip (VoIP), and cellular plans who have had their "unlimited services" cancelled because they (ta-da) moved too much data. It seems unlimited doesn't really mean unlimited. I could provide links to such information, but the sites tends to be full of wild ranting language, plus I don't want to single out just a few companies. Do the search above and you'll find examples for any type of service you desire.
While I can empathize with the ranters who've found out that unlimited just means "without a predefined limit", as a network professional I understand the basis for these service cancellations. It would be nice if the marketing hype-sters could be honest enough to stop using the term "unlimited", but then no user would sign up for an honest broadband service stupid enough to define limits when competitors are shouting about "unlimited plans".
All IP-based broadband systems consist of a series of hops or links, each with a predefined maximum data throughput. All commercial broadband services try to handle as many customers as they can sign up. Therefore the performance a user sees is merely a function of how many other users are active at that instant, how much data they are trying to push through at that instant, and what is the limiting throughput of the system bottlenecks. As a business person seeking to make money, would you prefer to keep 100 users paying $80 monthly to each move 100MB of data per month (10,000MB/month), or prefer to keep the one user paying $80 monthly to move 10GB (10,000MB) of data per month? While this is an extreme example, as soon as a few of the 100MB/month users complain to the broadband service about their high-speed internet seeming pretty slow speed, the solution is obvious to the business-minded. Canceling the "unlimited service" of the one user moving 10,000MB/month will effectively double the performance of the other 100 users with no added expenses and a mere loss of $80 per month of income. Failing to cancel the "unlimited service" of the one heavy user risks causing 10 or 20 of the other 100 light users to change services with a potential monthly income loss of hundreds or even thousands of dollars. I am not saying this is honest to cancel "unlimited service" based on high usage. I am just saying it is understandable and makes business sense.
How is this cancellation legal? Easy - just read the huge terms of service contract you agree to when you sign up for unlimited data service. To generalize some typical clauses in an unlimited cellular service plan:
- You agree to only use it for internet web browsing and email checking
- You agree to not download or upload files
- You agree to not use streaming media or peer-to-peer file sharing
- You agree to not run any application servers or data services
- You agree to not use the service as a replacement for a wired data circuit
- You agree to not use the service as a backup for a wired data circuit
- You agree that the service provider can cancel the service without notice if your usage impacts the operation of the service or other users of the service
In other words, you agree to use the cellular data service as a typical consumer with a notebook PC or PDA who spends at most an hour or two daily accessing the internet. I hope by now you can see how difficult it will be to fool any cellular service provider for long that your telemetry data system was just a normal consumer.
Friday, September 29, 2006
Cellular data - like a DSL or Cable Modem, but ...
Most potential users assume cellular data modems are just a newer form of the old Hayes AT-style analog dial-up modems - you know, your old ATDT {phone-number} interface. While there are a few old, rapidly obsoleting standards which work like this, all modern cellular data systems are IP-based. They operate much like your home Cable or DSL modem. Your cellular data modem links and authenticates to your ISP (or "carrier") and is assigned an IP address - just like your home Cable/DSL modem. There are no phone numbers to dial; your modem is "connected" as long as it is powered up. Your charges relate only to IP packets moved without any concept of minutes connected.
But ... marketing hype-aside, current and near-term cellular systems are NOT broadband as you or I would use that term. Ever used a cell phone and had a call drop? A voice garbled beyond recognition? No signal now even when you had one an instant ago? The same variability applies to cellular data networks. Cell towers do their best to share the air waves with all users; thus the speed and latency in your data movement is deeply impacted by both location and what other cellular users are doing.
In my world it is even worse ... this meaning people who use IP networks primarily for telemetry or data collection with small, cyclic polls for data. While you'd think this would be a natural fit for cellular data networks, it turns out to be fairly abnormal when viewed in the context of how the standards have been evolving. Every new advance in cellular data networks is aimed at pumping up throughput for web browsing, email exchange, or image/music downloads. New advances are aimed at your average human user with a PDA, notebook computer, or iPod; users who pay lots of cash per month for a single account with little concern for Return-On-Investment (ROI). Parents of teenagers know this best - what is the ROI of the $50 to $200 monthly the average "wired" teenager seems to spend? My youngest daughter spent an amazing three years during high school working part-time at a noisy place with video games and a big dancing mouse to pay for her cell phone usage.
In old-fashioned network terms, these are connection-oriented paradigms where larger latency & overhead is invested to initiate the connection as a tradeoff to having less cost to move each fragment of a large amount of data. Without going into too much detail, understand that traditional digital cellular voice calls can be viewed as small streaming media sessions. Each cell phone negotiates a strict series of repeated tiny time-periods during which it can send the next small digitized and compressed portion of your conversation. You can visualize this as an impossible juggling act where a few dozen assistants arranged in a star around an old juggling pro set up a rhythm and tempo that passes their pins in and out without a hiccup. Each pin must be launched at the exact correct instant to find an empty hand waiting on the other side. (Note that CDMA uses a different paradigm than these GSM "slots", but the need to share a limited resource is the same.)
The 2G/2.5G cellular data networks (slightly past state-of-the-art) functioned by just mimicking a voice call but substituting small chunks of pure data for the compressed slices of voice. Later advances to these standards allowed the tower and data modems to negotiate more or fewer of the tiny time-periods per second to better match the actual data throughput. Thus your perceived data network throughput can grow or shrink as the tower as fewer or more voice calls to handle. But breaking data up into a whole series of contiguous tiny time periods separated by overhead is very inefficient. So a key evolution in the latest standards is the ability of the tower to in effect negotiate consolidating a block of contiguous tiny time periods into fewer, longer time period.
Ok, enough over-simplified details - back to why telemetry data is abnormal in this world of "Cellular Broadband". Lets say every 15 minutes I send a Modbus/RTU poll that consists of 8 bytes of data into my 400kbps to 3mbps "Broadband" connection ... well, I'll get my blazingly fast 100 bytes response back in from 2 to 5 seconds. Hmm, sounds a lot like the performance of an old 600bps (600 baud) radio modem! So cellular data networks have fairly large latency when small infrequent amounts of data are moved. This goes back to the "juggler" paradigm I mentioned before. If your cellular device has no data to send after some number of seconds, the cell tower asks it to "stop juggling" - your device gives back its allocated tiny time-period(s) to be reused by other voice or data devices. After all, there are just so many of these periods to be shared by all users. So the process of the tower and data modem reallocating these tiny time-period(s) is the primary source of this large, variable latency.
Web browsers won't notice this latency since once the web page request is sent up, the page content just flows rapidly down in multiple TCP/IP streams without the explicit poll/response behavior of a telemetry session. Since the data exchange between the tower and cell modem is active and heavy, the tower does its best to bump up and allocate as much bandwidth to the cell modem as it can spare. This is where the elusive "Broadband" performance is able to peek out.
Today, your data modem needs to send data at least every 40 seconds to avoid this latency, but with 3G this will drop to every 3 seconds - which would be cost prohibitive. You say just get an unlimited plan? Sorry, no such thing, but that will be my next blog entry.
Want more details? See Also:
http://www.gsmworld.com/index.shtml
http://electronics.howstuffworks.com/cell-phone.htm/printable
But ... marketing hype-aside, current and near-term cellular systems are NOT broadband as you or I would use that term. Ever used a cell phone and had a call drop? A voice garbled beyond recognition? No signal now even when you had one an instant ago? The same variability applies to cellular data networks. Cell towers do their best to share the air waves with all users; thus the speed and latency in your data movement is deeply impacted by both location and what other cellular users are doing.
In my world it is even worse ... this meaning people who use IP networks primarily for telemetry or data collection with small, cyclic polls for data. While you'd think this would be a natural fit for cellular data networks, it turns out to be fairly abnormal when viewed in the context of how the standards have been evolving. Every new advance in cellular data networks is aimed at pumping up throughput for web browsing, email exchange, or image/music downloads. New advances are aimed at your average human user with a PDA, notebook computer, or iPod; users who pay lots of cash per month for a single account with little concern for Return-On-Investment (ROI). Parents of teenagers know this best - what is the ROI of the $50 to $200 monthly the average "wired" teenager seems to spend? My youngest daughter spent an amazing three years during high school working part-time at a noisy place with video games and a big dancing mouse to pay for her cell phone usage.
In old-fashioned network terms, these are connection-oriented paradigms where larger latency & overhead is invested to initiate the connection as a tradeoff to having less cost to move each fragment of a large amount of data. Without going into too much detail, understand that traditional digital cellular voice calls can be viewed as small streaming media sessions. Each cell phone negotiates a strict series of repeated tiny time-periods during which it can send the next small digitized and compressed portion of your conversation. You can visualize this as an impossible juggling act where a few dozen assistants arranged in a star around an old juggling pro set up a rhythm and tempo that passes their pins in and out without a hiccup. Each pin must be launched at the exact correct instant to find an empty hand waiting on the other side. (Note that CDMA uses a different paradigm than these GSM "slots", but the need to share a limited resource is the same.)
The 2G/2.5G cellular data networks (slightly past state-of-the-art) functioned by just mimicking a voice call but substituting small chunks of pure data for the compressed slices of voice. Later advances to these standards allowed the tower and data modems to negotiate more or fewer of the tiny time-periods per second to better match the actual data throughput. Thus your perceived data network throughput can grow or shrink as the tower as fewer or more voice calls to handle. But breaking data up into a whole series of contiguous tiny time periods separated by overhead is very inefficient. So a key evolution in the latest standards is the ability of the tower to in effect negotiate consolidating a block of contiguous tiny time periods into fewer, longer time period.
Ok, enough over-simplified details - back to why telemetry data is abnormal in this world of "Cellular Broadband". Lets say every 15 minutes I send a Modbus/RTU poll that consists of 8 bytes of data into my 400kbps to 3mbps "Broadband" connection ... well, I'll get my blazingly fast 100 bytes response back in from 2 to 5 seconds. Hmm, sounds a lot like the performance of an old 600bps (600 baud) radio modem! So cellular data networks have fairly large latency when small infrequent amounts of data are moved. This goes back to the "juggler" paradigm I mentioned before. If your cellular device has no data to send after some number of seconds, the cell tower asks it to "stop juggling" - your device gives back its allocated tiny time-period(s) to be reused by other voice or data devices. After all, there are just so many of these periods to be shared by all users. So the process of the tower and data modem reallocating these tiny time-period(s) is the primary source of this large, variable latency.
Web browsers won't notice this latency since once the web page request is sent up, the page content just flows rapidly down in multiple TCP/IP streams without the explicit poll/response behavior of a telemetry session. Since the data exchange between the tower and cell modem is active and heavy, the tower does its best to bump up and allocate as much bandwidth to the cell modem as it can spare. This is where the elusive "Broadband" performance is able to peek out.
Today, your data modem needs to send data at least every 40 seconds to avoid this latency, but with 3G this will drop to every 3 seconds - which would be cost prohibitive. You say just get an unlimited plan? Sorry, no such thing, but that will be my next blog entry.
Want more details? See Also:
http://www.gsmworld.com/index.shtml
http://electronics.howstuffworks.com/cell-phone.htm/printable
Introduction
Hello and welcome to my blog. I am scheduled to update this at least weekly, although at times I may be more prolific.
I have worked in pushing industrial protocols through Ethernet and IP for nearly 2 decades. This means using TCP/IP or UDP/IP to communicate between devices on a local or even world-wide scale. At present my job involves use of cellular networks, so most of the blog will focus on "adventures" in fooling poorly-written Ethernet applications to talk to a remote IP address.
Topics to cover:
I have worked in pushing industrial protocols through Ethernet and IP for nearly 2 decades. This means using TCP/IP or UDP/IP to communicate between devices on a local or even world-wide scale. At present my job involves use of cellular networks, so most of the blog will focus on "adventures" in fooling poorly-written Ethernet applications to talk to a remote IP address.
Topics to cover:
- How to write cellular/satellite friendly host applications
- How to work around poorly written host applications
- Over time I'll slowly discuss various common industrial protocols and how well they do or don't work to remote IP addresses.
Subscribe to:
Posts (Atom)