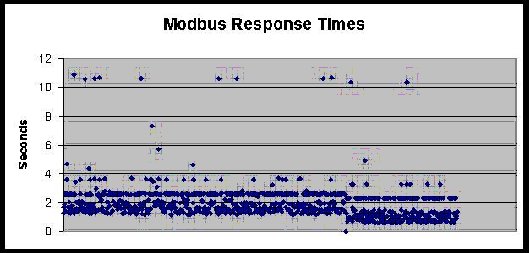
For example, here is a chart of 1000 Modbus/RTU polls over cellular TCP/IP. There is a random delay between polls of 30 seconds to 30 minutes. The patterns are rather striking: most polls complete in between 1 to 2 seconds, but there is clearly some systematic "aliasing" causing responses to complete in 2.8, 3.8, and 10.8 seconds.
After years of troubleshooting customers systems, I have been creating a running document and commentary on Bad things host apps do. I will be publishing these things over time in this blog. But to summarize:
- The default OS timeout on opening TCP Sockets may be too short.
- Attempting to open TCP sockets to unresponsive remotes must be a controlled process, since retries cost money.
- Since all packets and retries cost money, all aspects of the implemented protocol must be controlled and adjustable.
- OS stack calls may not return if the OS fails to detect a response or socket failure.
- Responses from the remote could take 15 to 60 seconds.
- TCP segment fragmentation and reassembly is exaggerated; can have many seconds of delay between fragments.
- TCP sockets idle longer than 5 minutes often go away without error or detection.
- Every byte your application sends (or resends) costs your customer money.
No comments:
Post a Comment